In-House Data Science Platform- Is it Right for Your Company?
We value preferences. When we started cnvrg.io, we were data science consultants helping enterprises incorporate AI into their business model. Every data scientist we worked with had their own tool preferences, used their own language and leveraged their own open source tools. We were also quite attached to our process for certain projects. While I used Python for all of my work, my colleague used R. While I swore by TensorFlow for my deep learning framework, my co-founder preferred the ease of Keras. The thing is, we understand the need for tool agility and customization. When an organization builds its own in-house platform, they get to build it based on their team's needs. And, it’s fun! You get to find creative ways to solve problems which is what data scientists like best. The only dilemma is, most of the time you were not hired to build and manage a data science platform. You were probably hired to build and deploy high impact machine learning models.
Be that as it may, you might still prefer to build your own data science platform from scratch. After years developing, iterating and testing cnvrg.io, we’d like to share a few things to consider before embarking on this journey.
Building Data Science Platforms Is in Our Blood
As data scientists, we are naturally builders and problem solvers. If we want to solve a problem, we simply build our own solution. In most cases we have the skills, tools, and knowledge to do so. Before switching to cnvrg.io, many of our customers already had internal data science systems or were in the process of creating one. As their needs for the platform became more complex, they decided to seek alternative solutions. Instead of building a full stack data science platform, they decided to invest more time building models and solving complex problems.
So, when you consider building your own in-house data science solution, there are a few things to consider:
1. Unlimited tool flexibility
No doubt that there is a plethora of open source tools out there at our disposal. But managing all the different tools so you can leverage them is a challenge.

Whether it’s R, Python, SQL, Scikit-learn, Hadoop, spark, Tensorflow, Keras, Jupyter - the list continues - you need a central place to bring all the pieces of the data science puzzle together. Just the thought of downloading Tensorflow brings great pain. Perhaps this might look familiar.
-
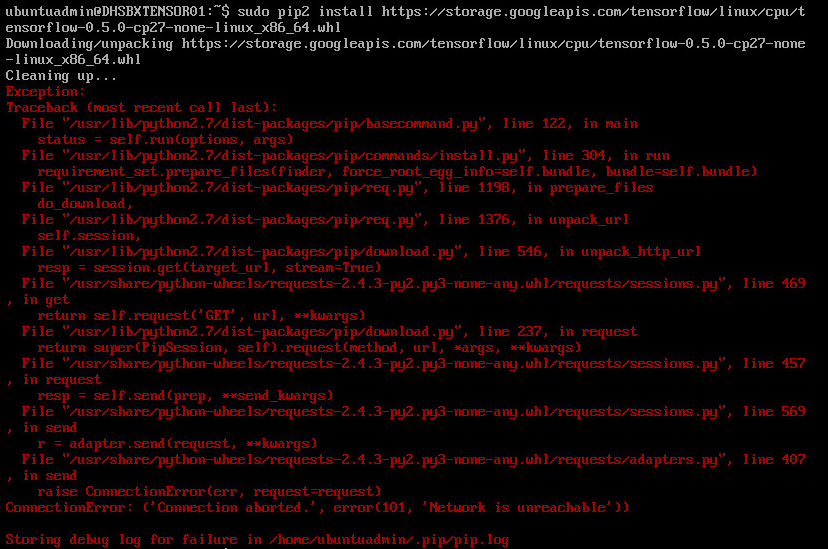
Error Installing TensorFlow -
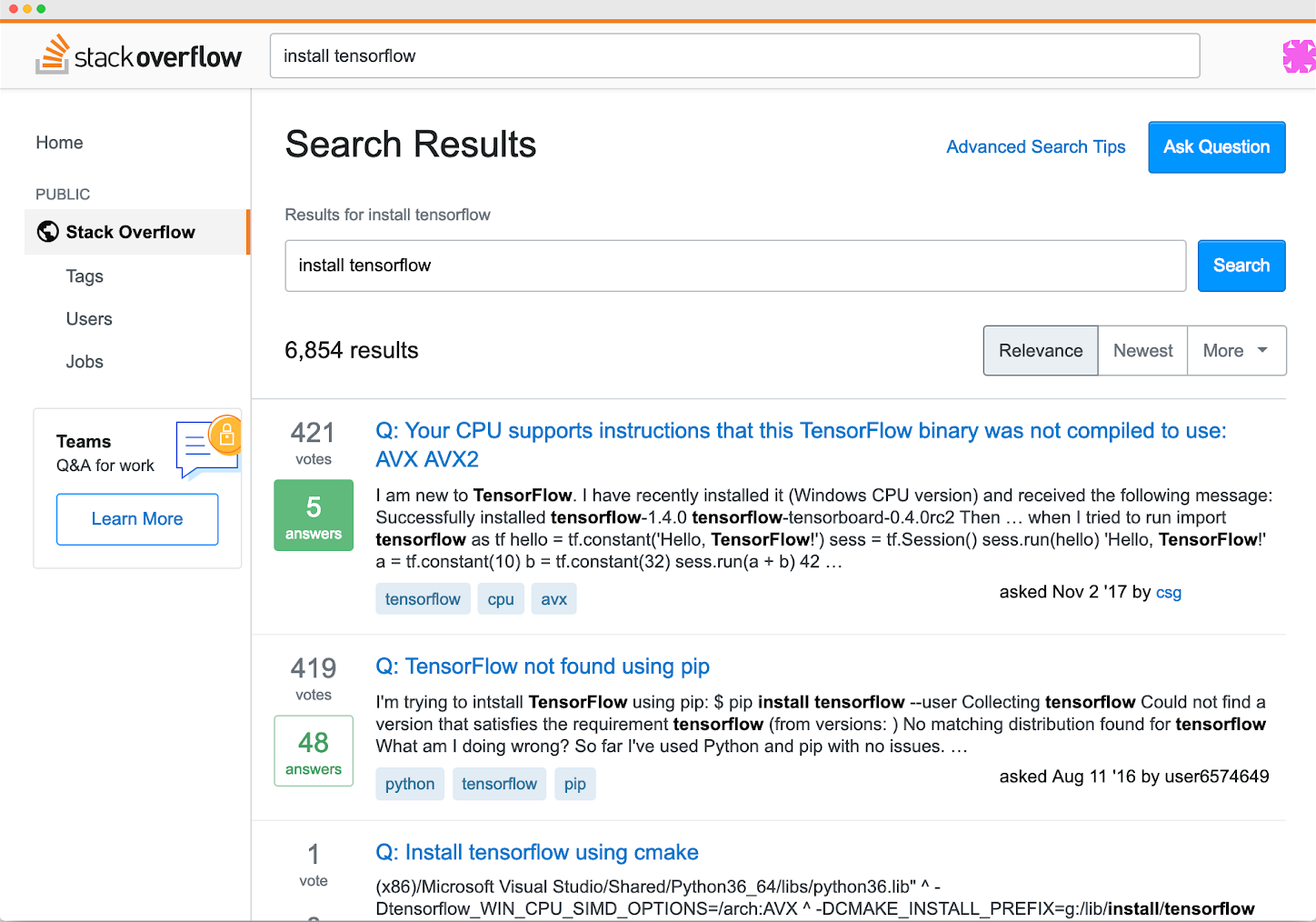
StackOverflow common questions
Create a system that easily integrates with all the tools necessary for your team. Additionally, tools are constantly adapting and developing. Be sure to plan for the future by building an open infrastructure that can integrate new tools.
2. Reproducibility
There are many manual systems in which companies can support reproducible data science. Companies have used Excel files, Notebooks, Docker, Git etc. Unfortunately, humans are imperfect and will sometimes miss a few key elements when documenting work. Our post ‘Research – an important role in reproducible data science’ highlights the challenges of documenting and reproducing research. Having one central location for all your data science activities can help solve the issue of tracking. By automatically documenting and storing each process, data scientists are able to backtrack and reproduce projects and review research validity. With this
3. Team management
It’s often said that data scientists work in silos. One challenge that teams have is unifying and syncing their work. Simple team organization such as task management, transitioning between responsibilities, reporting, and progress tracking can all accelerate the data science process if centralized. Considering methods of communication, and creating easy UI to make transitions seamless will save time. Not only that, but it will avoid frustration from team members. Depending on your team, projects might involve researchers, data engineers or machine learning engineers, and even DevOps or IT. Smoothly transitioning between tasks can carry communication barriers as well as technical inefficiency. That means building components that can be shared with the team to save time coding and supporting reusable machine learning. That way team members - whether they are data scientists or not - can rapidly build new models. It’s important to consider platform elements that carry out the entire workflow without blockages. And, it's recommended to use product managers to consult in this task, in order to do it right.
4. Resource management and scalability
Whether you’re building machine learning models or running models in production - compute power is inevitable. An organized system for
Secondly, be prepared for the best (or worst). It’s crucial for your platform to have the ability to connect to existing
5. Usability and design
When it comes to a data science platform, functionality is first. But,
Building Intelligent Machine Learning
Building intelligent machines is something we - data scientists - do best. When deciding whether or not to build an internal data science platform, consider what you were hired to do. In order to bring value to your company as a data scientist, you need to produce results. The goal of data science platforms is to help data scientists focus on the magic - the algorithms. Commercial data science platforms have evolved. cnvrg.io was built to facilitate any data science workflow and any use case. Whether it be computer vision, NLP, reinforcement learning, big data analytics or classic machine learning, you’ll always have the resources you need to produce (and reproduce) results.
Want to learn more about cnvrg.io data science platform?
Schedule a Live Demo HERE