You’re an AI expert. A deep learning Ninja. A master of machine learning. You’ve just completed another iteration of training your awesome model. This new model is the most accurate you have ever created, and it’s guaranteed to bring a lot of value to your company.
You’re an AI expert. A deep learning Ninja. A master of machine learning. You’ve just completed another iteration of training your awesome model. This new model is the most accurate you have ever created, and it’s guaranteed to bring a lot of value to your company.
But...
You reach a road block, holding back your models potential. You have full control of the model throughout the process. You have the capabilities of training it, you can tweak it, and you can even verify it using the test set. But, time and time again, you reach the point where your model is ready for production and your progress must take a stop. You need to communicate with DevOps, who likely has a list of tasks to the floor that
There is another way...
Publish your models on Kubernetes. Kubernetes is quickly becoming the cloud standard. Once you know how to deploy your model on
How to deploy models to production using Kubernetes
You’ll never believe how simple deploying models can be. All you need is to wrap your code a little bit. Soon you’ll be able to build and control your machine learning models from research to production. Here’s how:
Layer 1- your predict code
Since you have already trained your model, it means you already have
Below you’ll see a sample code that takes a sentence as an input, and returns a number that represents the sentence sentiment as predicted by the model. In this example, an IMDB dataset was used to train a model to predict the sentiment of a sentence.
import keras
model = keras.models.load_model("./sentiment2.model.h5")
def predict(sentence):
encoded = encode_sentence(sentence)
pred = np.array([encoded])
pred = vectorize_sequences(pred)
a = model.predict(pred)
return a[0][0]
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results*Tip
To make deploying even easier, make sure to track all of your code dependencies in a requirements file.
Layer 2- flask server
After we have a working example of the
The way to achieve this is to spawn a flask server that will accept the input as arguments to its requests, and return the model’s prediction in its responses.
from flask import Flask, request, jsonify
import predict
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def run():
data = request.get_json(force=True)
input_params = data['input']
result = predict.predict(input_params)
return jsonify({'prediction': result})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8080)In this small
Layer 3 — Kubernetes Deployment
And now, on to the final layer! Using
apiVersion: apps/v1
kind: Deployment
metadata:
name: predict-imdb
spec:
replicas: 1
template:
spec:
containers:
- name: app
image: tensorflow/tensorflow:latest-devel-py3
command: ["/bin/sh", "-c"]
args:
- git clone https://github.com/itayariel/imdb_keras;
cd imdb_keras;
pip install -r requirements.txt;
python server.py;
ports:
- containerPort: 8080You can see in the file that we declared a Deployment with a single replica. Its image is based
In this command, it clones the code from Github, installed the requirements and spins up the flask server written.
*Note: feel free to change the clone command to suit your needs.
Additionally, it's important to add a service that will expose deployment outside of
apiVersion: v1
kind: Service
metadata:
name: predict-imdb-service
labels:
app: imdb-server
spec:
ports:
- port: 8080
selector:
app: imdb-server
type: NodePortSend it to the cloud
Now that we have all files set, it's time to send the code to the Cloud.
Assuming you have a running
kubectl apply -f deployment.ymlThis command will create our deployment on the cluster.
kubectl apply -f service.ymlDoing this command will create a service that will expose the endpoint to
Use the command `
curl http://node-ip:node-port/predict \
-H 'Content-Type: application/json' \
-d '{"input_params": "I loved this videoLike, love, amazing!!"}'
Wrapping it up - It’s Aliiiive!
Easy huh? Now you know how to publish models to the internet using Kuberentes. And, with just a few lines of code. It actually gets easier.
cnvrg.io model deployment
cnvrg.io provides an end-to-end platform that allows data scientists to manage, build and automate machine learning from research to production. One of the core features of cnvrg.io is the automation of model deployment. With just a single click, a data scientist can create a production-ready environment that can serve millions of requests to their model.
For every deployment environment, cnvrg.io will set up a Kubernetes cluster with all the tools integrated to help you monitor your models in real-time (
Additionally, the cnvrg.io platform has integrated Istio for advanced A/B testing functionalities, webhooks, alerts and more. It’s so easy to use you’ll be surprised this solution wasn’t in your life earlier.
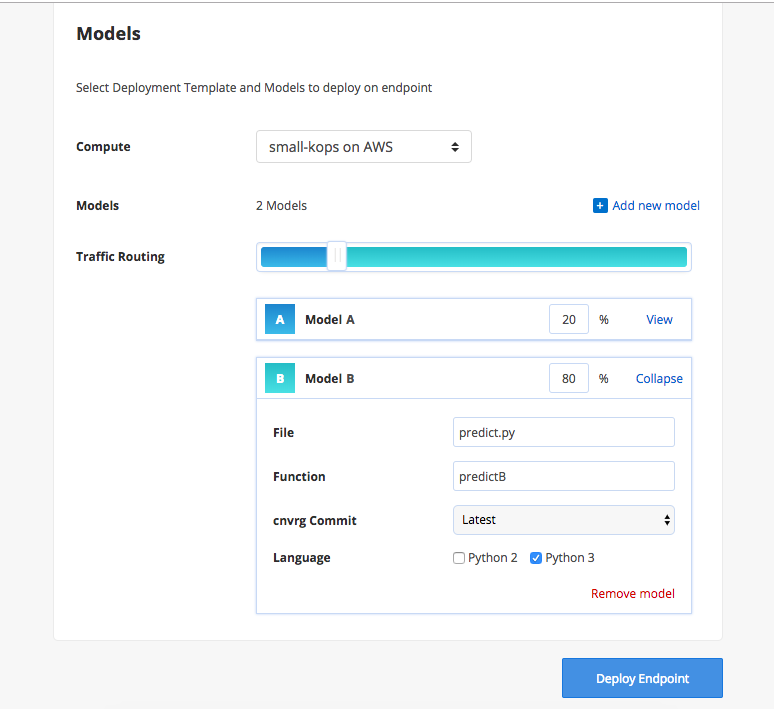
So. Go on. Take your own models and deploy away!
You can follow the full example and code from above here. You can also join our Kubernetes Workshop and learn how to set up Kubernetes for your machine learning workflows
Register for a free online workshop
How to set up Kubernetes for all your machine learning workflows