Use Spot Instances to Save Money on Machine Learning Cloud Costs
Building machine learning is expensive. It’s expensive not only because of the high salaries of data scientists, but also the high cost of cloud compute. If you want your model to be built properly, you can't compromise compute power. The best way to reduce the cost of
This article will present a way for you to save on cloud costs so you can focus on the model that needs to be built. Not only that, but it will increase the ROI of your model, which will make your stakeholders happy.
Why is machine learning development so expensive?
Machine learning models are inherently expensive to build. Building a model often requires a lot of computational power. Depending on the size of your dataset, it might require massive CPU/Memory instances to handle larger datasets with applications like Spark for distributed computing. Or, if you’re training deep learning, high-end GPU instances are almost always a must. These use-cases are pretty common in the machine learning world, and the expensive
The second costly condition of machine learning is that it requires a lot of experimentation. Training a model to converge usually does not happen in a single run. In fact, many of our users report running hundreds and thousands of experiments per machine learning project. To produce the best model possible, these costs are unavoidable when searching for your champion model.
The solution: Spot instances
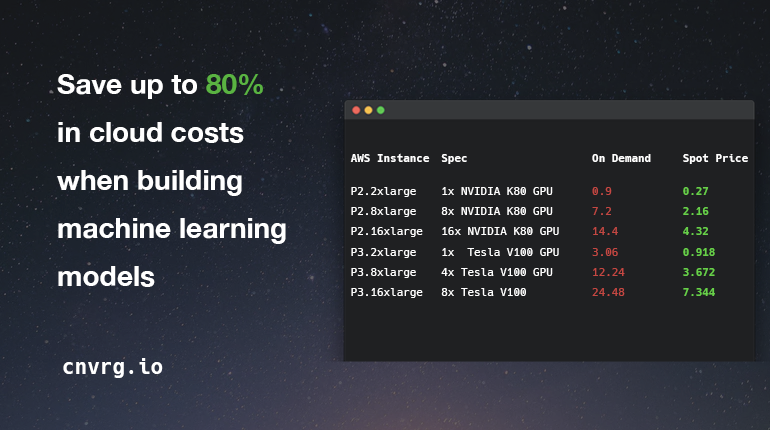
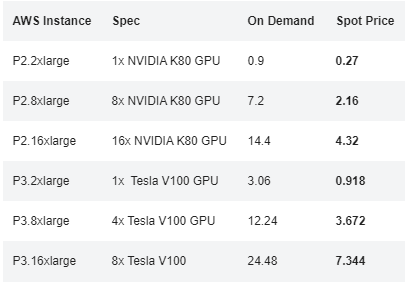
Spot instances on AWS are your way of saving up to 80% in cloud costs when building models. According to AWS documentation “A Spot Instance is an unused EC2 instance that is available for less than the On-Demand price”. What does that mean? It means that AWS has many unused servers available at a given time. In order to get the most out of these servers, AWS has found a clever way to monetize them by selling them at a major discount. With Spot
GPU Instances on AWS and their OnDemand vs. spot price
This hidden gem is almost too good to be true. So, before you get carried away with excitement, there are two things to keep in mind before using spot instances:
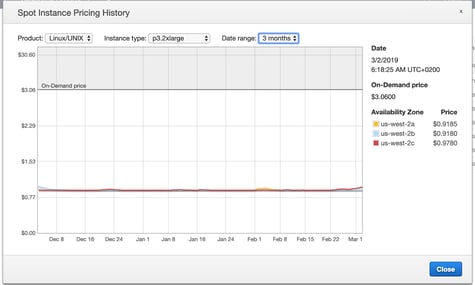
1. Price surges - The spot price is determined by demand and bidding trends. This means that when the demand for that instance is high, the spot price increases by the second. Just like Uber, you want to avoid busy times. You can optimize your savings by monitoring fluctuations in prices with Spot Instance Pricing History and by running at low demand times.
2. Termination - Spot instances can be automatically terminated by AWS with only 2-minute notice. This can happen if your bidding price is low and another person has bid higher, or if all on-demand instances are being used.
Spot instances and your machine learning
So, we have summarized spot instances, as well as their pros and cons. How does this fit into your machine learning workflow? As outlined above, there are a few risks to using spot instances. While it’s great to save all that money, what if you train a model for a week and then your instance is terminated? How can you take that risk? That is where checkpoints and S3 come into play.
A lot of machine and deep learning frameworks have introduced checkpointing capabilities which allow data scientists and developers to save versions of the model created during training. Then, if something happens, you can continue training from last saved checkpoint.
How to create model checkpoints
To be more practical, we created a few code samples to help you checkpoint a model in TensorFlow and Keras training. We're simply using the Keras callbacks API, and more specifically ModelCheckpoint
checkpoint = ModelCheckpoint(‘checkpoints/weights_checkpoint.h5’, monitor='val_acc', verbose=1, save_best_only=True, mode='max')
callbacks = [checkpoint]
model.fit(X, Y, validation_split=split, epochs=epochs, batch_size=batch_size, callbacks=callbacks, verbose=0)```
Load a checkpoint and continue training
# Reload model
model = load_model(‘checkpoints/weights_checkpoint.h5’)
# Train
model.fit(X, Y, validation_split=split, epochs=epochs, batch_size=batch_size, callbacks=callbacks, verbose=0)<br>
We would recommend to also store some meta data about the latest store checkpoint. It can be in the filename or even a simple text file.
Summary
Data science teams that use cnvrg.io automatically benefit from
Customers have trained massive GANs over weeks on spot-instances, saving them thousands of dollars. You think that’s too good to be true? See for yourself with a free demo.



