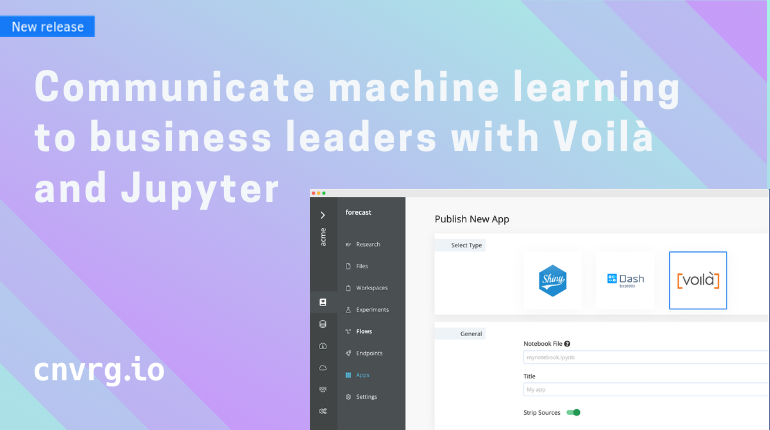
Every machine learning project starts with research. Whether you are working in a corporation or in academia, it’s likely you are already familiar with the research phase of data science. And, if you’ve embarked on this research journey before, you may have started with a single paper, which

A typical view of a data scientist’s browser while conducting research
Two weeks later, you’re able to proceed with building your machine learning or deep learning models, quite possibly forgetting the bathroom break in which you rediscovered article #1 that prompted your breakthrough machine learning predictive model to begin with.
Needless to say, the research tunnel is a vibrant and unpredictable one, leading in many directions, and provoking endless thought. The research process - unexpected as it is - can often be a hard one to retrace, let alone to reproduce.
The ugly-beautiful research phase
When discussing the data science reproducibility, most often you’ll hear about the importance of documenting experiments, hyperparameters, metrics, or how to track models and algorithms to prepare for someone who would replicate it. Unfortunately, a major process in the data science pipeline that is completely overlooked in reproducibility, is research. Research is the ugly-beautiful practice that consumes 2 weeks - prior to any coding or experimentation - where you sit down and understand former attempts or learn from previously successful solutions.

As Jon Claerbout describes: “An article about computational results is advertising, not scholarship. The actual scholarship is the full software environment, code and data that produced the result.” What really makes it scholarship over advertising is the research that got you there to begin with.”
Why make reproducible research?
As stated in the rOpenSci Project’s Reproducibility Guide there are two main reasons to make reproducible research.
One might argue that it is redundant to do research for a problem you have already solved before. It can especially be overlooked when working in a fast-paced corporate environment. But, it’s likely that there are some exciting innovative solutions that you wouldn’t have encountered without research. Take for instance text classification - a rather simple and common machine learning task, where only in the past 30 days there were over 52 new papers published on Arxiv. Admittedly, not all of them will be related to the problem being solved, or even of superior quality, but they can spark new ideas and inspire you to try new approaches to solve your challenges.
Standardizing research reproducibility
Preparing data science research for reproducibility is easier said than done. There is no standardized way to document research, and the degree of documentation of research can vary between data scientists. Before starting cnvrg.io, we assisted companies in various data science projects. Time and time again, we continued to assist clients approaching the same problems, or had to reproduce projects that had been done before. We saw the important role research had in reproducing a project, and how much time could have been saved if proper documentation was available.
When cnvrg.io came to be, we integrated research deeply in the product, and created ways to standardize research documentation to make research reproducibility less daunting. The research center in cnvrg.io makes documentation of papers, discussions
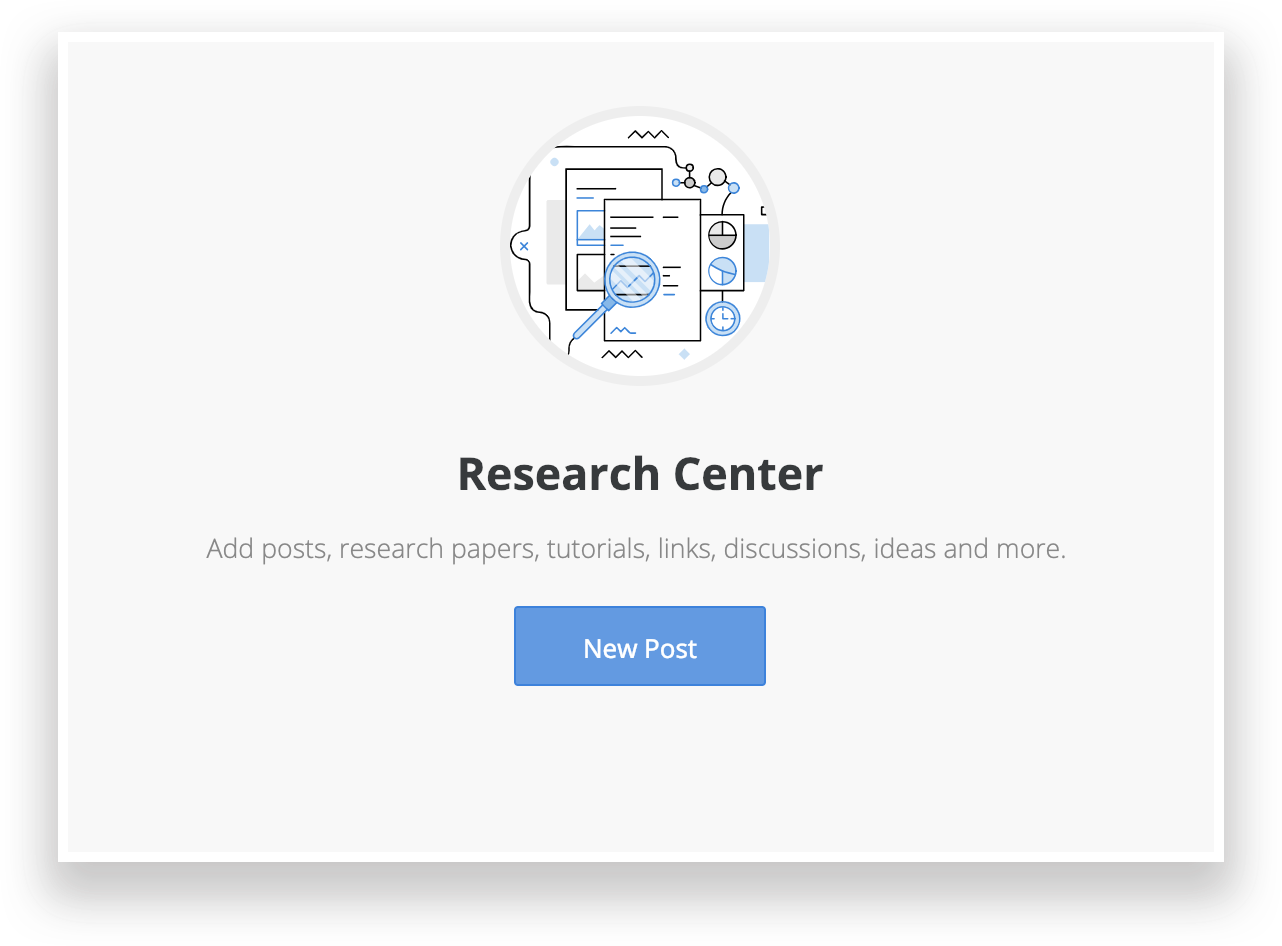
As data scientists continue to discover breakthroughs in machine learning, it's important to stick to our scientific roots. Embrace the power of research, and document every detail so that others can build from your well investigated conclusions. If anything, don’t you want your coworkers to experience the same trippy research journey you had the pleasure to embark on?
Seeking solutions for reproducible data science?
Sign up for a one-on-one demo with a cnvrg.io specialist